
Letzte Änderung am 30. Januar 2024 von Walter
Jeder, der sich eingehend mit Excel beschäftigt, wird irgendwann auf Pivot-Tabellen stoßen.
Pivot-Tabellen = Kreuztabellen
– das ist die Botschaft, die man dazu sogleich in Hilfe-Dateien, Foren und Büchern erhält. Doch was sind Kreuztabellen und weswegen soll das Überkreuzen von Tabellenspalten bei der Datenauswertung etwas bringen?
Meine Erfahrung ist: Das Überkreuzen ist so abstrakt, dass man am besten gar nicht erst versucht (es sei denn, man beschäftigt sich als Mathematiker oder Informatiker beruflich sowieso damit), die dahinterliegenden Prozesse zu verstehen. Wie so oft bei abstrakten Zusammenhängen ist es gut, ihre Wirkung in der Praxis zu sehen. Bezogen auf Pivot-Tabellen bedeutet das, dass man einfach einmal eine Pivot-Tabelle erstellt und sich anschaut, wozu das führt und welche Experimente man damit vornehmen kann.
Das Erstellen kann komplett nach Anleitung geschehen. Eine solche wird nachfolgend gegeben.
Erstellen von Pivot-Tabellen
-
Ausgangspunkt sei eine vorhandene Arbeitstabelle.
-
Man klickt in irgendeine Zelle der Tabelle und ruft Menu <Einfügen – Pivot-Tabelle> auf.
-
Ist die Ausgangstabelle als Liste (oder „intelligente Tabelle“) formatiert, erscheint ihr Name im Fenster „PivotTabelle erstellen“:
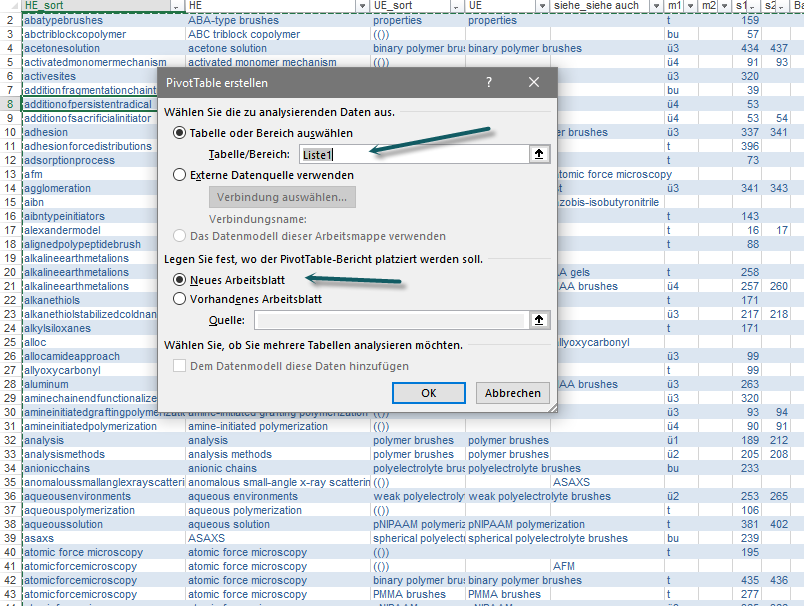
Bild 1: Fenster „PivotTabelle erstellen“. Der Name der intelligenten Tabelle, die als Ausgangstabelle dient, lautet hier „Liste 1“.
-
Wäre die Ausgangstabelle keine Liste, müsste der Tabellenbereich in Form einer üblichen Bereichsangabe (z.B. A1:E20) eingetragen werden.
-
Wichtig ist, bei Platzierung „Neues Arbeitsblatt“ zu wählen, damit die Pivot-Tabelle, die über ganz eigene Funktionen verfügt, nicht mit anderen Bereichen des Arbeitsblatts in Konflikt gerät; außerdem ist die Übersichtlichkeit so viel besser, als wenn sich die Pivot-Tabelle auf demselben Arbeitsblatt wie die Ausgangstabelle befinden würde.
-
Als nächstes erscheint entweder das „klassische“ Fenster mit Bereichen für Zeilen-, Spalten- und Wertfelder (Bild 2 a) oder das „moderne“ Fenster, in dem man aufgefordert wird, Felder auszuwählen (Bild 2 b). In beiden Fällen wird rechts der Pivot-Aufgabenbereich angezeigt.
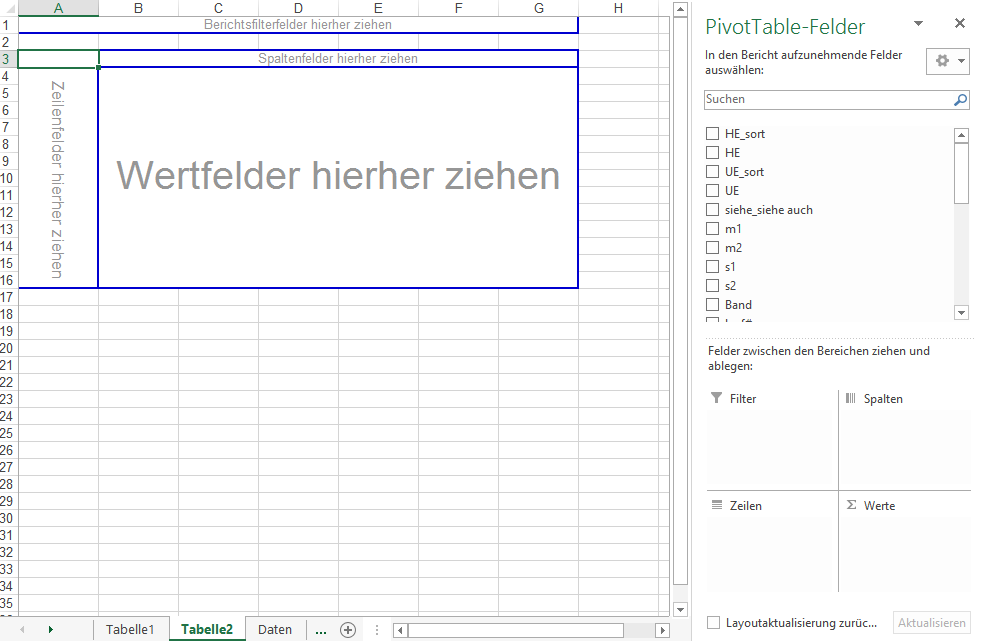
Bild 2 a: Klassisches Fenster zum Einfügen einer Pivot-Tabelle

Bild 2 b: Modernes Fenster zum Einfügen einer Pivot-Tabelle
- Im Pivot-Aufgabenbereich (PivotTabelle-Felder) können die Felder durch Anklicken ausgewählt werden. Standardmäßig landet ein angeklicktes Feld im Zeilenbereich. Von hier kann es bei Bedarf in die anderen Bereiche verschoben werden. Bei der Einstellung „klassisch“ werden die Felder im Zeilenbereich nebeneinander, also spaltenweise angeordnet (Bild 3 a); bei der Einstellung „modern“ stehen sie mit hierarchischer Einrückung untereinander in der ersten Spalte der Pivot-Tabelle (Bild 3 b).

Bild 3 a: Spaltenweise Anordnung der per Checkmarke gewählten Auswertefelder
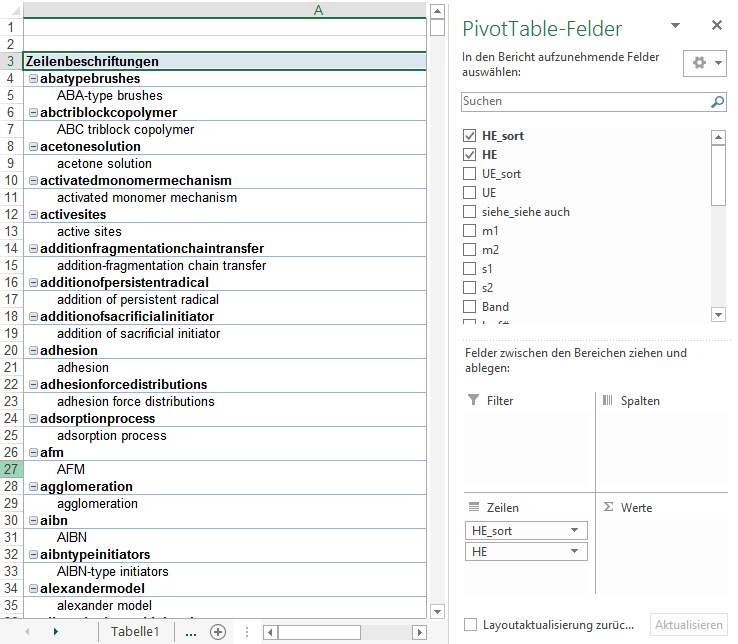
Bild 3 b: Hierarchische Einrückung bei der modernen Anordnung der Auswertefelder
Um von der modernen zur klassischen Anordnung zu kommen, muss eine Einstellung in den Pivot-Tabellen-Optionen vorgenommen werden, und zwar muss das entsprechende Häkchen gesetzt werden:
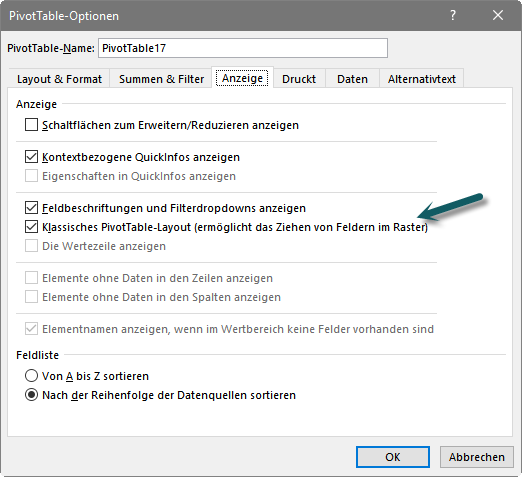
Bild 4: Bewusste Herbeiführung und Festsetzung der klassischen Anordnung (in den Optionen zu Pivot-Tabellen)
Nach OK werden die Daten nebeneinander angeordnet. Der umgekehrte Weg (also aus einer bestehenden klassischen Anordnung eine moderne machen) scheint nicht so einfach möglich zu sein. Aber man kann auf der Basis derselben Ausgangsdaten einfach eine neue zusätzliche Pivot-Tabelle erstellen.
| Die Zahl der Pivot-Tabellen, die man zu einer Ausgangstabelle erstellen kann, ist unbegrenzt. |
Die klassische Anordnung ist dann von Vorteil, wenn man eine hierarchische Sicht auf die Daten haben möchte. Das ist z. B. bei der Registererstellung (Indexe zu Büchern oder Zeitschriften) sehr hilfreich.